3 OverHAuL’s Design
In this thesis we present OverHAuL (Harness Automation with LLMs), a neurosymbolic AI tool that automatically generates fuzzing harnesses for C libraries through LLM agents. In its core, OverHAuL is comprised by a triplet of LLM ReAct agents [1]—each with its own responsibility and scope—and a codebase oracle reserving the given project’s analyzed source code. An overview of OverHAuL’s process is presented in Figure 3.1, detailed in Section 3.2. The objective of OverHAuL is to streamline the process of fuzz testing for unfuzzed C libraries. Given a link to a git repository [2] of a C library, OverHAuL automatically generates a new fuzzing harness specifically designed for the project. In addition to the harness, it produces a compilation script to facilitate building the harness, generates a representative input that can trigger crashes, and logs the output from the executed harness.
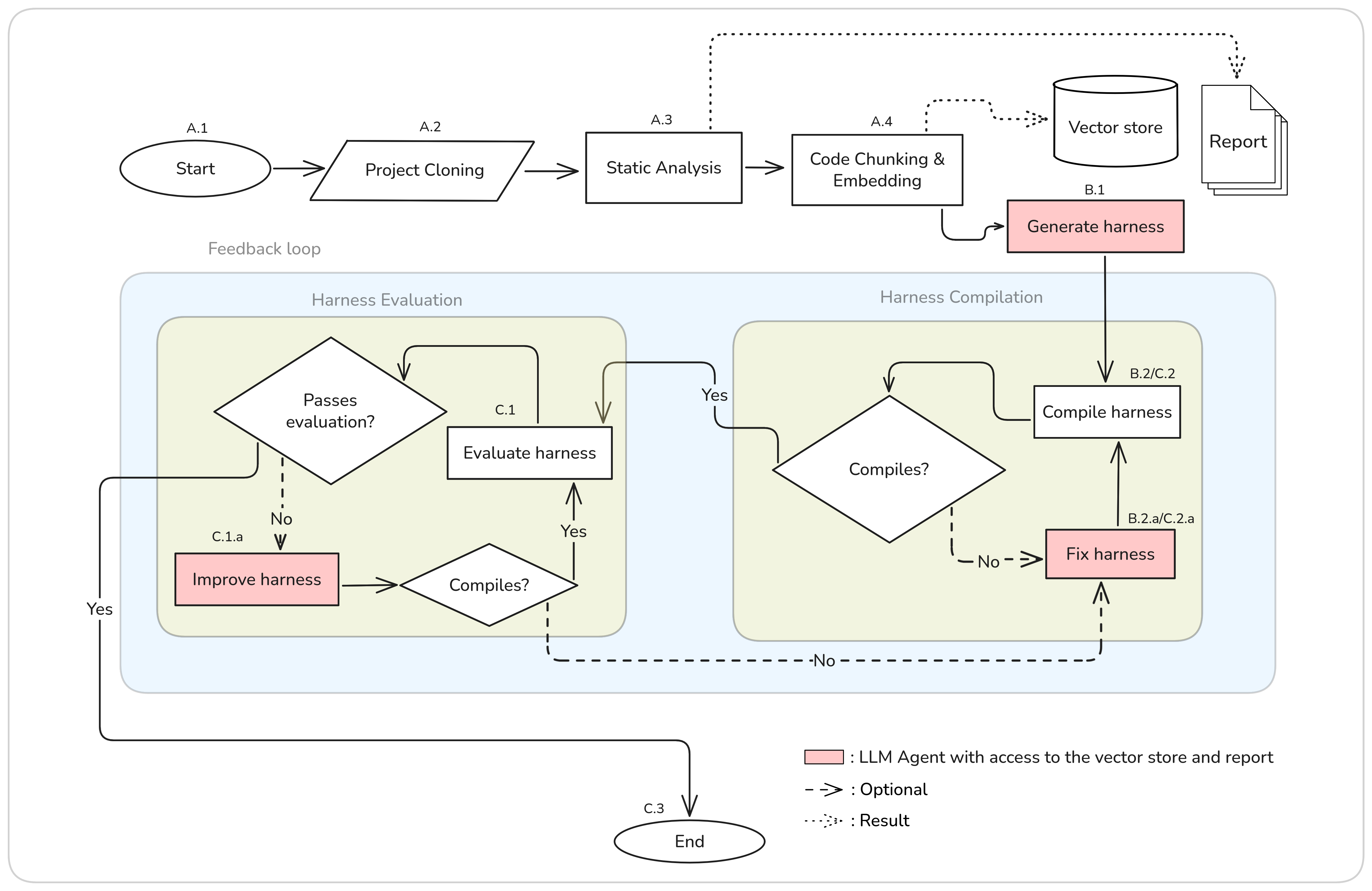
OverHAuL utilizes autonomous ReAct agents which inspect and analyze the project’s source code. The latter is stored and interacted with as a set of text embeddings [3], kept in a vector store. Both approaches are, to the best of our knowledge, novel in the field of automatic fuzzing harnesses generation. OverHAuL also implements an evaluation component that assesses in real-time all generated harnesses, making the results tenable, reproducible and well-founded. Ideally, this methodology provides a comprehensive and systematic framework for identifying previously unknown software vulnerabilities in projects that have not yet been fuzz tested.
As detailed in Section 5.4, OverHAuL does not expect and depend on the existence of client code or unit tests [4], [5], [6] nor does it require any preexisting fuzzing harnesses [7] or any documentation present [8]. Also importantly, OverHAuL is decoupled from other fuzzing projects, thus lowering the barrier to entry for new projects [7], [9]. Lastly, the user isn’t mandated to manually specify the function which the harness-to-be-generated must fuzz. Instead, OverHAuL’s agents examine and assess the provided codebase, choosing after evaluation the most optimal target function.
Finally, OverHAuL excels in its user-friendliness, as it constitutes a simple and easily-installable Python package with minimal external dependencies—only real dependency being Clang, a prevalent compiler available across all primary operating systems. This contrasts most other comparable systems, which are typically characterized by their limited documentation, lack of extensive testing, and a focus primarily on experimental functionality.1
3.1 Installation and Usage
The source code of OverHAuL is available in https://github.com/kchousos/OverHAuL. OverHAuL can be installed by cloning the git repository locally, creating and enabling a Python3.10 virtual environment [11] (optional, but recommended) and installing it inside the environment using Python’s PIP package installer [12], like in Listing 3.1.
$ git clone https://github.com/kchousos/overhaul; cd overhaul
...
$ python3.10 -m venv .venv
$ source ./.venv/bin/activate
$ pip install .
...
$ overhaul --help
usage: overhaul [-h] [-c COMMIT] [-m MODEL] [-f FILES [FILES ...]]
[-o OUTPUT_DIR] repo
Generate fuzzing harnesses for C/C++ projects
positional arguments:
repo Link of a project's git repo, for which to generate
a harness.
options:
-h, --help show this help message and exit
-c COMMIT, --commit COMMIT
A specific commit of the project to check out
-m MODEL, --model MODEL
LLM model to be used. Available: o3-mini, o3, gpt-4o,
gpt-4o-mini, gpt-4.1, gpt-4.1-mini, gpt-3.5-turbo, gpt-4
-f FILES [FILES ...], --files FILES [FILES ...]
File patterns to include in analysis (e.g. *.c *.h)
-o OUTPUT_DIR, --output-dir OUTPUT_DIR
Directory to clone the project into. Defaults to "output"
$To use OverHAuL, you need to provide a secret key for using OpenAI’s API service. This key can be either stored in a .env file in the root directory or exported in the shell environment:
Once these preliminary steps are completed, OverHAuL can be executed. The primary argument required by OverHAuL is the repository link of the library that is to be fuzzed. Additionally, users have the option to specify certain command-line flags, which allow them to control the checked-out commit of the cloned project, select the OpenAI LLM model from a predefined list, define specific file patterns for OverHAuL to search for, and determine the directory in which the project will be cloned. For a concrete example, we will use OverHAuL to create a new fuzzing harness for dvhar’s dateparsing C library and specify the LLM model to OpenAI’s gpt-4.1 model. The resulting command and its output is presented in Figure 3.2.

In this example, the dateparse repository is cloned into the ./output/dateparse directory, which is relative to the root directory of OverHAuL. Following a successful execution, the project’s directory will contain a new folder named harnesses, which will house all the generated harnesses formatted as harness_n.c—where n ranges from 1 to N-1, with N representing the total number of harnesses produced. The most recent and verifiably correct harness will be designated simply as harness.c. Additionally, the dateparse folder will include an executable script named overhaul.sh, which contains the compilation command necessary for the harness. A log file titled harness.out will also be present, documenting the output from the latest harness execution. Lastly and most importantly, there will be at least one non-empty crash file included, serving as a witness to the harness’s correctness. In the following sections, the intermediary steps between invocation and completion are disected and analyzed. The dateparse project is used as a running example.
3.2 Architecture
OverHAuL can be compartmentalized in three stages: First, the project analysis stage (Section 3.2.1), the harness creation stage (Section 3.2.2) and the harness evaluation stage (Section 3.2.3).
3.2.1 Project Analysis
In the project analysis stage (steps A.1–A.4), dateparse is ran through a static analysis tool named Flawfinder [13] and is sliced into function-level chunks, which are stored in a vector store. The results of this stage are a static analysis report and a codebase oracle, i.e. a vector store containing embeddings of function-level code chunks. Both resources are later available to the LLM agents. Flawfinder is executed with the dateparse directory as input and is responsible for the static analysis report. This report is considered a meaningful resource, since it provides the LLM agent responsible with the harness creation with some starting points to explore, regarding the occurrences of potentially vulnerable functions and/or unsafe code practices. Part of dateparse’s static analysis report is shown in Listing 3.2.
Flawfinder version 2.0.19, (C) 2001-2019 David A. Wheeler.
Number of rules (primarily dangerous function names) in C/C++ ruleset: 222
Examining ./dateparse.c
Examining ./dateparse.h
Examining ./test.c
FINAL RESULTS:
./dateparse.c:405: [4] (buffer) strcpy:
Does not check for buffer overflows when copying to destination [MS-banned]
(CWE-120). Consider using snprintf, strcpy_s, or strlcpy (warning: strncpy
easily misused).
......
./dateparse.c:2192: [1] (buffer) strlen:
Does not handle strings that are not \0-terminated; if given one it may
perform an over-read (it could cause a crash if unprotected) (CWE-126).
ANALYSIS SUMMARY:
Hits = 64
Lines analyzed = 2719 in approximately 0.04 seconds (61234 lines/second)
Physical Source Lines of Code (SLOC) = 1966
Hits@level = [0] 15 [1] 28 [2] 31 [3] 0 [4] 5 [5] 0
Hits@level+ = [0+] 79 [1+] 64 [2+] 36 [3+] 5 [4+] 5 [5+] 0
Hits/KSLOC@level+ = [0+] 40.1831 [1+] 32.5534 [2+] 18.3113 [3+] 2.54323
[4+] 2.54323 [5+] 0
Dot directories skipped = 1 (--followdotdir overrides)
Minimum risk level = 1
Not every hit is necessarily a security vulnerability.
You can inhibit a report by adding a comment in this form:
// flawfinder: ignore
Make *sure* it's a false positive!
You can use the option --neverignore to show these.
There may be other security vulnerabilities; review your code!
See 'Secure Programming HOWTO'
(https://dwheeler.com/secure-programs) for more information.The codebase oracle is created in the following manner: The source code is first chunked in function-level pieces by traversing the code’s Abstract Syntax Tree (AST) through Clang. Each chunk is represented by an object with the function’s signature, the corresponding filepath and the function’s body (see Listing 3.3). Afterwards, each function body is turned into a vector embedding through an embedding model. Each embedding is stored in the vector store. This structure is created and used for easier and more semantically meaningful code retrieval, and to also combat context window limitations present in LLMs.
File: dateparse/dateparse.c
Signature: void (struct parser *, int, int)
Code:
static void setOffset(struct parser* p, int i, int len){
strncpy(p->offsetbuf, p->datestr+i, len);
p->offsetbuf[len] = 0;
}
File: dateparse/dateparse.c
Signature: void (struct parser *, char *)
Code:
static void setFullMonth(struct parser* p, char* month){
strcpy(p->mobuf, month);
}
File: dateparse/dateparse.c
Signature: int (const char *, long long *, int *, int)
Code:
int dateparse(const char* datestr, date_t* t, int *offset, int stringlen){
struct parser p;
*t = 0;
if (!stringlen)
stringlen = strlen(datestr);
if (parseTime(datestr, &p, stringlen))
return -1;
return parse(&p, t, offset);
}3.2.2 Harness Creation
Second is the harness creation stage (steps B.1–B.2). In this part, a “generator” ReAct LLM agent is tasked with creating a fuzzing harness for the project. The agent has access to a querying tool that acts as an interface between it and the codebase oracle. When the agent makes queries like “functions containing strcpy()”, the querying tool turns the question into an embedding and through similarity search returns the top k=5 most similar results—in this case, functions of the project. With this approach, the agent is able to explore the codebase semantically and pinpoint potentially vulnerable usage patterns easily.
The harness generated by the agent is then compiled using Clang and linked with the AddressSanitizer, LeakSanitizer, and UndefinedBehaviorSanitizer. The compilation command used is generated programmatically, according to the rules described in Section 3.5. If the compilation fails for any reason, e.g. a missing header include, then the generated faulty harness and its compilation output are passed to a new “fixer” agent tasked with repairing any errors in the harness (step B.2.a). This results in a newly generated harness, presumably free from the previously shown flaws. This process is iterated until a compilable harness has been obtained. After success, a script is also exported in the project directory, containing the generated compilation command. Dateparse’s compilation command is shown in Listing 3.4.
3.2.3 Harness Evaluation
Third comes the evaluation stage (steps C.1–C.3). During this step, the compiled harness is executed and its results evaluated. Namely, a generated harness passes the evaluation phase if and only if:
The harness has no memory leaks during its execution
This is inferred by the existence of
leak-<hash>files.A new testcase was created or the harness executed for at least
MIN_EXECUTION_TIME(i.e. did not crash on its own)When a crash happens, and thus a testcase is created, it results in a
crash-<hash>file.The created testcase is not empty
This is examined through
xxd’s output given the crash-file.
Similarly to the second stage’s compilation phase (steps B.2–B.2.a), if a harness does not pass the evaluation for whatever reason it is sent to an “improver” agent. This agent is instructed to refine it based on its code and cause of failing the evaluation. This process is also iterative. If any of the improved harness versions fail to compile, the aforementioned “fixer” agent is utilized again (steps C.2–C.2.a). All produced crash files and the harness execution output are saved in the project’s directory. An evaluation-passing harness generated for the dateparse project is presented in Listing 3.5, along with the associated crash input and execution output displayed in Listing 3.6 and Listing 3.7, respectively.
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
#include "dateparse.h"
// ...
struct parser {
char mobuf[16];
};
// ...
static void setFullMonth(struct parser* p, char* month){
strcpy(p->mobuf, month);
}
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
// Allocate a parser instance on the heap.
struct parser *p = (struct parser*)malloc(sizeof(struct parser));
if (!p) {
return 0;
}
// Initialize parser with zeros.
memset(p, 0, sizeof(struct parser));
// Prepare month string input: ensure null-terminated string for strcpy.
char *month = (char*)malloc(size + 1);
if (!month) {
free(p);
return 0;
}
memcpy(month, data, size);
month[size] = '\0'; // Null terminate to avoid overread in strcpy.
// Call the vulnerable function with fuzzed month string.
setFullMonth(p, month);
// Cleanup
free(month);
free(p);
return 0;
}xxd output.
00000000: 315e 5e5e 5e5e 5e5e 5e5e 5e5e 5e5e 5e5e 1^^^^^^^^^^^^^^^
00000010: 0a .INFO: Running with entropic power schedule (0xFF, 100).
INFO: Seed: 2365219758
INFO: Loaded 1 modules (3723 inline 8-bit counters): 3723 [0x67ccc0,
0x67db4b),
INFO: Loaded 1 PC tables (3723 PCs): 3723 [0x618d40,0x6275f0),
./harness: Running 1 inputs 1 time(s) each.
Running: crash-7fd6f4dd5d39420d6f7887ff995b4e855ae90c16
=================================================================
==10973==ERROR: AddressSanitizer: heap-buffer-overflow on address
0x7bcece9e00a0 at pc 0x000000526c0e bp 0x7fff3dc0aa20 sp 0x7fff3dc0a1d8
WRITE of size 18 at 0x7bcece9e00a0 thread T0
#0 0x000000526c0d in strcpy
(/home/kchou/Bin/Repos/kchousos/OverHAuL/output/dateparse/harness
+0x526c0d) (BuildId: d658684b8726dc7e8e768089710d13c96cfc81f0)
#1 0x000000585555 in setFullMonth
/home/kchou/Bin/Repos/kchousos/OverHAuL/output/dateparse/harnesses
/harness.c:18:2
#2 0x0000005853fd in LLVMFuzzerTestOneInput
/home/kchou/Bin/Repos/kchousos/OverHAuL/output/dateparse/harnesses
/harness.c:41:2
...
SUMMARY: AddressSanitizer: heap-buffer-overflow
(/home/kchou/Bin/Repos/kchousos/OverHAuL/output/dateparse/harness
+0x526c0d) (BuildId: d658684b8726dc7e8e768089710d13c96cfc81f0) in
strcpy
Shadow bytes around the buggy address:
0x7bcece9dfe00: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7bcece9dfe80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7bcece9dff00: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7bcece9dff80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7bcece9e0000: fa fa 00 00 fa fa 00 fa fa fa 00 fa fa fa 00 fa
=>0x7bcece9e0080: fa fa 00 00[fa]fa fa fa fa fa fa fa fa fa fa fa
0x7bcece9e0100: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x7bcece9e0180: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x7bcece9e0200: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x7bcece9e0280: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
0x7bcece9e0300: fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa fa
Shadow byte legend (one shadow byte represents 8 application bytes):3.3 OverHAuL Techniques
The fundamental techniques that distinguish OverHAuL in its approach and enhance its effectiveness in achieving its objectives are: The implementation of an iterative feedback loop between the LLM agents, the distribution of responsibility across a triplet of distinct agents and the employment of a “codebase oracle” for interacting with the given project’s source code.
3.3.1 Feedback Loop
The initial generated harness produced by OverHAuL is unlikely to be successful from the get-go. The iterative feedback loop implemented facilitates its enhancement, enabling the harness to be tested under real-world conditions and subsequently refined based on the results of these tests. This approach mirrors the typical workflow employed by developers in the process of creating and optimizing fuzz targets.
In this iterative framework, the development process continues until either an acceptable and functional harness is realized or the defined iteration budget is exhausted. The iteration budget N=10 is initialized at the onset of OverHAuL’s execution and is shared between both the compilation and evaluation phases of the harness development process. This means that the iteration budget is decremented each time a dashed arrow in the flowchart illustrated in Figure 3.1 is followed. Such an approach allows for targeted improvements while maintaining oversight of resource allocation throughout the harness development cycle.
3.3.2 React Agents Triplet
An integral design decision in our framework is the implementation of each agent as a distinct LLM instance, although all utilizing the same underlying model. This approach yields several advantages, particularly in the context of maintaining separate and independent contexts for each agent throughout each OverHAuL run.
By assigning individual contexts to the agents, we enable a broader exploration of possibilities during each run. For instance, the “improver” agent can investigate alternative pathways or strategies that the “generator” agent may have potentially overlooked or internally deemed inadequate inaccurately. This separation not only fosters a more diverse range of solutions but also enhances the overall robustness of the system by allowing for iterative refinement based on each agent’s unique insights.
Furthermore, this design choice effectively addresses the limitations imposed by context window sizes. By distributing the “cognitive” load across multiple agents, we can manage and mitigate the risks associated with exceeding these constraints. As a result, this architecture promotes efficient utilization of available resources while maximizing the potential for innovative outcomes in multi-agent interactions. This layered approach ultimately contributes to a more dynamic and exploratory research environment, facilitating a comprehensive examination of the problem space.
3.3.3 Codebase Oracle
The third central technique employed is the creation and utilization of a codebase oracle, which is effectively realized through a vector store. This oracle is designed to contain the various functions within the project, enabling it to return the most semantically similar functions upon querying it. Such an approach serves to address the inherent challenges associated with code exploration difficulties faced by LLM agents, particularly in relation to their limited context window.
By structuring the codebase into chunks at the level of individual functions, LLM agents can engage with the code more effectively by focusing on its functional components. This methodology not only allows for a more nuanced understanding of the codebase but also ensures that the responses generated do not consume an excessive portion of the limited context window available to the agents. In contrast, if the codebase were organized and queried at the file level, the chunks of information would inevitably become larger, leading to an increase in noise and a dilution of meaningful content in each chunk [14]. Given the constant size of the embeddings used in processing, each progressively larger chunk would be less semantically significant, ultimately compromising the quality of the retrieval process.
Defining the function as the primary unit of analysis represents the most proportionate balance between the size of the code segments and their semantic significance. It serves as the ideal “zoom-in” level for the exploration of code, allowing for greater clarity and precision in understanding the functionality of individual code segments. This same principle is widely recognized in the training of code-specific LLMs, where a function-level approach has been shown to enhance performance and comprehension [15]. By adopting this methodology, we aim to foster a more robust interaction between LLM agents and the underlying codebase, ultimately facilitating a more effective and efficient exploration process.
3.4 High-Level Algorithm
A pseudocode version of OverHAuL’s main function is shown in Algorithm 1, illustrating the workflow depicted in Figure 3.1 and incorporating the methods explained in Sections 3.2 and 3.3. Notably, within this algorithm, the HarnessAgents() function acts as an interface that connects the “generator”, “fixer”, and “improver” LLM agents. The specific agent utilized during each invocation of HarnessAgents() depends on the function’s arguments. As a result, the harness variable encapsulates all generated, fixed, or improved harnesses. Since both the “fixer” and “generator” agents are accessed through the HarnessAgents() function, the related continue statements correspond to the next iterations of fixing or improving a harness. This design choice streamlines the overall algorithm, making it more abstract and easier to comprehend.
3.5 Scope
Currently, OverHAuL is designed to generate new harnesses specifically for medium-sized C libraries. Given the inherent complexity of dealing with C++ projects, this is not a feature yet supported within the system.
The compilation command utilized by OverHAuL is created programmatically. It incorporates the root directory along with all subdirectories that conform to a predefined set of common naming conventions. Additionally, the compilation process uses all C source files identified within these directories. Crucially, it is important that no main() function is present in any of the files to ensure successful compilation. For this reason any files or directories that include “test”, “main”, “example”, “demo”, or “benchmark” in their paths are systematically excluded from the compilation process. This exclusion also decreases the “noise” in the oracle, as these files do not constitute part of the core library and would therefore not contain any functions meaningful to the LLM agents.
Lastly, No support for build systems such as Make or CMake [16], [17] is yet implemented. Such functionality would exponentially increase the complexity of the build step and is beyond the scope of this thesis.
3.6 Implementation
In creating the codebase oracle, we employ the “libclang” Python package [18] to slice functions based on the AST capability provided by Clang. As detailed in Section 3.3.3, the intermediate output consists of a list of Python dictionaries, with each dictionary storing a function’s body, signature, and corresponding file path. Each chunk of function code is then converted into an embedding using OpenAI’s “text-embedding-3-small” model [19] and stored in a FAISS vector store index [20]. This index is mapped to a metadata structure that contains the aforementioned function data—specifically the actual function body, signature, and file path. When a search is conducted on the index, the results returned are the embeddings. The responses that the LLM agent receives are derived from the corresponding metadata entries of each embedding.
All LLM agents and components are developed using the DSPy library, a declarative Python framework for LLM programming created by Stanford’s NLP research team [21]. DSPy offers built-in modules and abstractions that facilitate the composition of LLMs and prompting techniques, such as Chain of Thought and ReAct (Listing 3.8). Each agent within OverHAuL is an instance of DSPy’s ReAct module [22], accompanied by a custom Signature [23]—displayed in Appendix C. DSPy was selected over other contemporary LLM libraries, such as LangChain and Llamaindex [24], [25], because of its user-friendliness, logical abstractions, and efficient development process—qualities that are often lacking in these alternative libraries [26], [27], [28].
Repository cloning is executed using the --depth 1 flag to minimize disk storage usage and reduce the size of artifacts.
The current implementation of OverHAuL sits at 1,254 source lines of Python code.
3.6.1 Development Tools
The development of OverHAuL incorporates a variety of tools aimed at enhancing functionality and efficiency. Notably, “uv” is a Python package and project manager written in Rust that serves as a replacement for Poetry. Additionally, “Ruff,” a code linter and formatter also developed in Rust, contributes to code quality by enforcing consistent formatting standards. The project also employs “MyPy,” the widely-used static type checker for Python, to ensure type correctness. Testing is facilitated through “PyTest,” a robust Python testing framework. Lastly, “pdoc” is utilized as a Static Site Generator (SSG) to automate the creation of API documentation2 [29], [30], [31], [32], [33].
3.6.2 Reproducibility
OverHAuL’s source code is available at https://github.com/kchousos/OverHAuL. Each benchmark run was conducted within the framework of a GitHub Actions workflow, resulting in a detailed summary accompanied by an artifact containing all cloned repositories. These artifacts are the compressed result directories described in Section 4.1.1 and provide the essential components necessary for the reproducibility each project’s results, as described in Section 3.1. All benchmark runs can be conveniently accessed at https://github.com/kchousos/OverHAuL/actions/workflows/benchmarks.yml.