OverHAuL: Harness Automation with LLMs
Unleash the fuzz on your C codebase

Department of Informatics & Telecommunications, University of Athens
July 7, 2025
Introduction
Motivation
- Memory unsafety is and will be prevalent
- Software is safe until it’s not
- Humans make mistakes
- Humans now use Large Language Models (LLMs) to write software
- LLMs make mistakes
Result: Bugs exist
Goal
A system that:
- Takes a bare C project as input
- Generates a new fuzzing harness from scratch using LLMs
- Compiles it
- Executes it and evaluates it
Overview
Introduction- Background
- Related work
- OverHAuL
- Results
- Future work
- Discussion/Conclusion
Background
Fuzzing
Fuzzing
What is fuzzing? [1]
Fuzzing
Why fuzz?
The purpose of fuzzing relies on the assumption that there are bugs within every program, which are waiting to be discovered. Therefore, a systematic approach should find them sooner or later.
Fuzzing
Success stories
- Heartbleed vulnerability, OpenSSL [2] (CVE-2014-0160)
- Easily found with fuzzing ⇒ Preventable
- Shellshock vulnerabilities, Bash (CVE-2014-6271)
- Mayhem (FKA ForAllSecure) [3]
- Cloudflare
- OpenWRT
Fuzzing
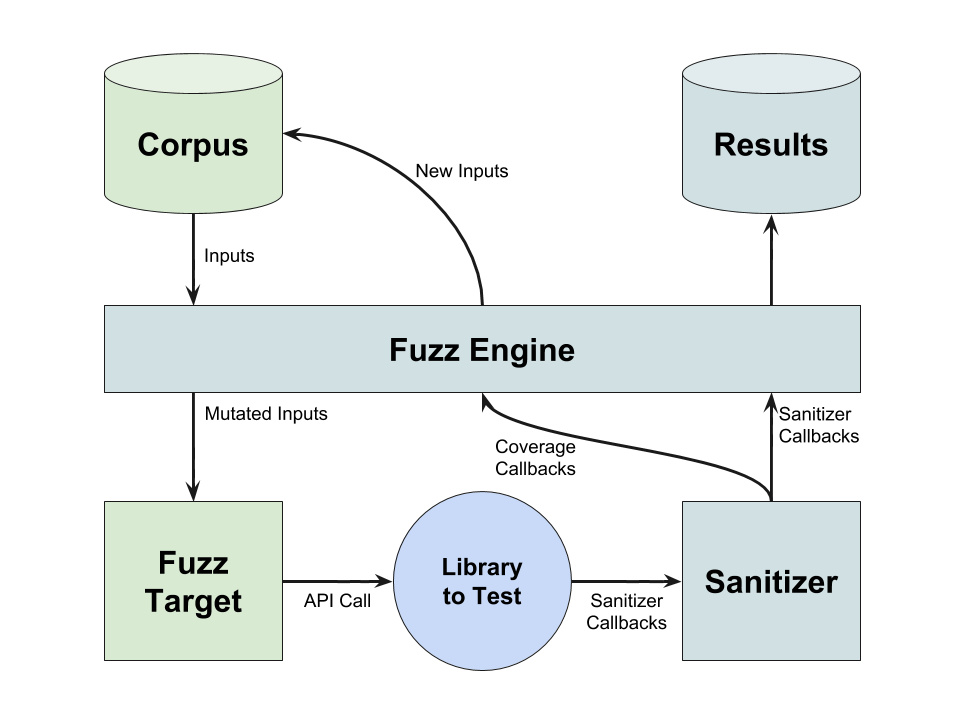
Fuzzer implementations
LibFuzzer
Fuzz target/harness
Fuzz target
A function that accepts an array of bytes and does something interesting with these bytes using the API under test [4].
AKA fuzz driver, fuzzer entry point, harness.
LibFuzzer
Harness structure
- Entry point called repeatedly with mutated inputs.
- Feedback-driven: uses coverage to guide mutations.
- Best for libraries, not full programs.
Fuzzing
Difficulties
- Relatively unknown practice, especially compared to TDD
- Upfront cost of writing harnesses
- Cost of examining and evaluating crashes
Large Language Models (LLMs)
LLMs
Machine Learning (ML) models trained on vast amounts of data, implemented through transformers [7].
Most powerful and well-known LLMs are Generative-Pretrained-Transformers (GPTs):
LLMs
Prompting
Interaction happens in a chat-like function. The process of querying an LLM is called prompting.
LLMs
Prompting
The different types of prompting techniques include:
LLMs
For programming
In recent years, LLMs have disrupted the world of software engineering.
Both web-based interfaces and AI-assisted IDEs [18], [19] have seen exponential growth in popularity and adoption.
These developments have converged in the creation of a new type of software engineering: Vibecoding [20].
LLMs
Challenges in programming
- Knowledge limited to training data → Hallucinations
- Limited context window → Inapplicable to large codebases
The same challenges apply when using LLMs to write fuzzing harnesses.
Neurosymbolic AI
Neurosymbolic AI (NeSy AI)
What is it?
AI systems that integrate neural and ML methods with symbolic execution systems and tools [21].
A more accurate and robust cognitive model for problem solving.
NeSy AI
What does it solve?
In regards to LLMs and established AI practices, NeSy AI is seen as the answer to explainability, attribution and reliability problems that we face today [22], [23].
NeSy AI
What’s its state?
NeSy AI as a research is still in its adolescence.
In fuzzing in particular, there are only a few tools developed that combine ML methodologies and symbolic systems for harness generation.
Related work
Automated fuzzing/testing
- KLEE [24]: Symbolic execution tool designed to automatically generate high-coverage test cases.
- FUDGE [25]: Closed-source program for automatic harness generation of C/C++ projects based on existing client code.
- FuzzGen [26]: Automatic harness generation through whole system analysis. Uses programs using the API under test to generate a dependency graph of the API functions.
LLM-assisted fuzzing
- IRIS [27]: Neurosymbolic system using LLMs for static analysis, based on user-provided CWEs.
- ProphetFuzz [28]: LLM-assisted fuzzing for option combinations.
- OSS-Fuzz-Gen [29]: Automatic generation of harnesses for OSS-Fuzz projects [30]. Preexisting harnesses needed.
Not many exist ¯\_(ツ)_/¯.
OverHAuL
Overview
Overview
C project’s git repository link ⇒ New fuzzing harness, with:
- Working crash input
- Compilation shell script
- Logged output
Automated process with the help of LLM agents.
How is it different?
- No prior fuzzing infrastructure is required
- Straight-forward installation process
- Harness generation through iterative improvements and runtime evaluation
- Decoupled from other fuzzing projects
Research questions
Research questions
- RQ1: Can OverHAuL generate working harnesses for unfuzzed C projects?
- RQ2: What characteristics do these harnesses have? Are they similar to man-made harnesses?
- RQ3: How do different LLM techniques influence the generated harnesses?
- RQ4: How do different symbolic techniques affect the generated harnesses?
Scope
Scope
- Limited to C libraries
- Expects relatively simple project structure
- Code either in root or in common-named subdirs (e.g.
src/) - Any file or directory with
main,testorexamplesubstring is ignored - No
main()function, or only exists in some file that is ignored by the above
- Code either in root or in common-named subdirs (e.g.
- Build systems not supported
- Harness is compiled with a predefined command
Architecture/Pipeline

Step 1: Repo cloning
- Simple
git clone --depth 1is used for quicker downloads and less storage usage- Cloned repo now exists in
output/<repo-name>
Step 2: Static analysis
Flawfinder [32] is executed with the project directory as input.
This step provides the LLM with some starting points to explore, regarding usage of potentially vulnerable functions etc.
Step 3: Code chunking and vector store
Source code of the given project is chunked in function-level units.
Each unit is turned into an embedding and stored in a vector store.
Step 4: Initial harness generation
A ReAct LLM agent is called to create a new harness for the given project.
It has access to a tool acting as a frontend to the vector store. The agent can make queries such as “Functions that use strcpy() in their code” and the tool will:
- Turn the query to an embedding
- Use that to perform a search on the vector store
- Return the top 5 most relevant results to the agent
Step 5: Harness compilation
After a harness has been generated, it is written in harnesses/harness.c, relative to the given project’s root.
It then is compiled, with the compilation command being of the following form:
clang -g3 -fsanitize=fuzzer,address,undefined,leak harnesses/harness.c <relevant .c files> -I <relevant dirs with header files> -o harnessStep 6: Harness evaluation
The generated harness is executed and evaluated. The harness passes the check iff:
- There are no memory leaks (i.e. no
leak-<hash>files) - A new testcase was created (i.e. a new
crash-<hash>file) OR the harness executed for at leastMIN_EXECUTION_TIME(i.e. did not crash on its own) - The created testcase is not empty
Techniques used
Feedback loop
The pipeline is not as straightforward as initially presented (Noticed the circular arrows?).
- If the generated harness doesn’t compile, an LLM agent is called to fix it — given it’s compilation error.
- If the generated harness doesn’t pass the evaluation, an LLM agent is called to improve it — given it’s output and the reason that it fails.
- If the improved harness doesn’t compile, it is yet again sent to the previous agent.
Vector store for code exploration
Source code is processed and chunked using Clang [33]. The chunks are function-level units, found to be a sweet-spot between semantic significance and size [34], [35].
This results in a list of Python dicts, each containing a function’s body, signature and filepath.
Each chunk’s function code is then turned into an embedding using OpenAI’s “text-embedding-3-small” model.
A FAISS [36] vector store is created. Each function embedding is stored in it (with the same order, as to correspond with the previous list containing the metadata).
LLM triplets
Instead of one LLM agent being responsible for the whole process, each of the three agents have one specific task.
This allows more exploration per run, e.g. the improver agent might explore a different path that the generator agent had rejected.
Also keeps context window limitations manageable, since they are shared between the agents.
Accurate flowchart

Abandoned techniques
Abandoned techniques
- Zero-shot harness generation
- Chain of Thought [15] LLM instances instead of ReAct agents
- Naive source code concatenation
- File-based
read_toolfor ReAct agents
Implementation details
Implementation details
Everything LLM-related was accomplished using DSPy, a declarative Python framework “for programming instead of prompting”, developed by Stanford’s NLP research team [37].
The code chunking used the libclang Python package [38]. The vector store was implemented using Meta’s FAISS library [36].
Results
Test repos
OverHAuL was tested using a corpus of ten C libraries, randomly* picked from clib’s1 [39] package index. These libraries are:
Sample results
Let’s examine the latest benchmark run (GH action run 16097203944):
Parameters
- Model used: OpenAI’s gpt-4.1-mini
- Harness timeout: 5 mins
- Max iterations of feedback loop: 10
Results
- Runtime: 1h 9m 20s
- Successfully harnessed projects: 10/10
Sample results
Dateparse harness
#include <stddef.h>
#include <stdint.h>
#include <string.h>
#include <stdlib.h>
#include "dateparse.h"
// No artificial size limit to allow fuzzer to explore full input size for boundaries
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
// Allocate buffer with extra byte for null termination
char *input_str = (char *)malloc(size + 1);
if (!input_str) {
return 0;
}
memcpy(input_str, data, size);
input_str[size] = '\0';
date_t parsed_date = 0;
int offset = 0;
// Array of string lengths targeting boundary conditions (including 0 = internal strlen)
size_t test_lens[] = {0, size, size > 0 ? size - 1 : 0, 12, 13, 14};
for (size_t i = 0; i < sizeof(test_lens) / sizeof(test_lens[0]); i++) {
size_t len = test_lens[i];
if (len <= size) {
dateparse(input_str, &parsed_date, &offset, (int)len);
}
}
free(input_str);
return 0;
}Sample results
Input that produces the crash
$ xxd crash-cb0da18a3a4b25864cc4611107790ca150dfa63f
00000000: 302f 30c3 202f 312c 0f0f 0f0f 0f0f 0f0f 0/0. /1,........
00000010: 0f0f 0f0f 0f0f 0f0f 0f0f 0f0f 0f0f 0f0f ................
00000020: 0f0f 0f0f 0f0f 0f0f 0fff ffff ffff ffff ................
00000030: ffff ffff ffff ffff ffff ffff ffff ffff ................
00000040: ffff ffff ffff ffff ffff ffff ffff ffff ................
00000050: ffff ffff ffff ffff ff0f 0f0f 0f0f 0f0e ................
00000060: 0f0f 2a21 8100 062f 3061 bc70 c5c5 ..*!.../0a.p..Sample results
mpc harness
#include <stddef.h>
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
// Dummy definitions to allow compilation - actual definitions may differ,
// but these suffice for the harness and match observed fields used.
typedef struct {
int dummy;
} mpc_input_t;
typedef struct {
char **expected;
int expected_num;
} mpc_err_t;
// mpc_malloc and mpc_realloc wrappers likely use standard malloc/realloc internally.
static void *mpc_malloc(mpc_input_t *i, size_t size) {
(void)i; // unused in this mock
return malloc(size);
}
static void *mpc_realloc(mpc_input_t *i, void *ptr, size_t size) {
(void)i; // unused
return realloc(ptr, size);
}
// Implement the actual function under test from earlier observation:
static void mpc_err_add_expected(mpc_input_t *i, mpc_err_t *x, char *expected) {
(void)i;
x->expected_num++;
x->expected = mpc_realloc(i, x->expected, sizeof(char*) * x->expected_num);
x->expected[x->expected_num-1] = mpc_malloc(i, strlen(expected) + 1);
strcpy(x->expected[x->expected_num-1], expected);
}
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
if (size == 0) return 0; // no input, nothing to fuzz
mpc_input_t input;
memset(&input, 0, sizeof(mpc_input_t));
// Initialize mpc_err_t with one initial expected string for realistic state
mpc_err_t err;
err.expected_num = 1;
err.expected = (char **)malloc(sizeof(char*));
if (!err.expected) return 0;
err.expected[0] = (char *)malloc(2);
if (!err.expected[0]) {
free(err.expected);
return 0;
}
err.expected[0][0] = 'X';
err.expected[0][1] = '\0';
// We'll split input data into multiple (up to 3) parts to call mpc_err_add_expected multiple times
size_t num_calls = 3;
size_t chunk_size = size / num_calls;
if (chunk_size == 0) chunk_size = size; // for very small size
for (size_t call = 0; call < num_calls; call++) {
size_t offset = call * chunk_size;
size_t sz = (call == num_calls - 1) ? (size - offset) : chunk_size;
if (sz == 0) break;
// Allocate null-terminated string for expected
char* expected_input = (char*)malloc(sz + 1);
if (!expected_input) break;
memcpy(expected_input, data + offset, sz);
expected_input[sz] = '\0';
mpc_err_add_expected(&input, &err, expected_input);
free(expected_input);
}
// Clean up all allocated memory
for (int i = 0; i < err.expected_num; i++) {
free(err.expected[i]);
}
free(err.expected);
return 0;
}Results vary!
Reproducibility
Reproducibility
- Each benchmark run was executed as a GitHub Actions workflow.
- Each run results in an artifact containing all the cloned repos, each with:
- All generated harnesses
- A compilation script
- The latest harness’ output
- All crash-files/testcases
RQs Answered
Research questions answered
RQ1
Can OverHAuL generate working harnesses for unfuzzed C projects?
- Yes
- For a corpus of 10 clib packages [39], OverHAuL is capable of generating harnesses for all 10 of them, overall
- The mean success rate per benchmark execution was ~80%, with the successfully harnessed projects varying per run
Research questions answered
RQ2
What characteristics do these harnesses have? Are they similar to man-made harnesses?
- It depends
- Most generated harnesses are straightforward and sound, mimicking human-written ones
- Although, some harnesses contain seemingly arbitrary checks or constrains
Research questions answered
RQ3
How do different LLM techniques influence the generated harnesses?
- Different LLM models performed relatively similar to each other
- Most successful benchmark runs were executed using gpt-4.1-mini
- Different prompting techniques were a lot more impactful
- Zero-shot prompting had expectedly unremarkable results
- Chain of Thought prompting showed little improvement
- ReAct yielded the most results, mainly due to the more sophisticated code exploration accompanying it by definition
Research questions answered
RQ4
How do different symbolic techniques affect the generated harnesses?
- Simple source code concatenation has obvious drawbacks, mainly due to context window limitations
- Access to tools that return file contents is a step forward, but still suffers with small context windows
- A function-level vector store is the most scalable approach, both when scaling in file or project size
Future work
Future work
Support for build systems (Makefile, CMake)
Support for other languages (C++, Python, Rust)
Support for different fuzzers (AFL++)
Support for and experimentation with different LLM providers/models
- Code-specific LLMs
More sophisticated evaluation methods
Experimentation with different chunking techniques
Testing of full clib index
More extensive comparison with Google’s OSS-Fuzz-Gen
Analysis of API usage/cost per execution
Packaging as GitHub Action
Conclusion
Conclusion
- OverHAuL demonstrates that LLMs can successfully automate the daunting task of fuzzing harness writing.
- The system achieves significant results with minimal prior setup, offering a promising pathway to improve code quality and security.
- While results are encouraging, challenges remain, with the biggest being scaling to more complex projects.
- Continued research and development will further empower software developers by lowering the barriers to fuzzing.
- OverHAuL is a step forward in leveraging AI for practical, impactful automation in software engineering.
Links
The project’s homepage is https://github.com/kchousos/overhaul
These slides can be found at https://kchousos.github.io/overhaul-presentation
The completed thesis can be found at https://kchousos.github.io/thesis



References

